いよいよ第1回と第2回のAmes/QSAR国際チャレンジプロジェクトの集計結果を使ってデータ解析を始めます。
解析の目的は、前回の最後に述べたコレです。
『MultiCASE社のBM_PHARMAと明治薬科大学モデルの「真の性能」はどちらが優れているのでしょうか?
この比較を実現するために、全てのモデルにおいてカバー率が100%のときの評価結果を解析的に推定してみましょう。』
さて、集計結果を格納したExcel表には
Project No列、Phase列、Teams列、Tool No列、QSAR tools (module)列
と
BA (%)、MCC、F1 score (%)、COV (%)
があります。
これらがプロジェクト論文から抽出された情報です。
一方、これら以外にもPC1列やJohnson Sb[COV (%)]列などなどが格納されていますが、これらは解析結果ですので追って解説していきます。
各行には個別のQSAR toolとその予測性能が記載されています。
(ちなみに、横方向の情報を「行」、縦方向の情報を「列」と言います)
Project No列には各QSAR toolが第1回と第2回のどちらのコンペで使われたものかが示されています。
Phase列は、第1回プロジェクトにおける3回のコンペのどれに相当するかが書かれています。
Teams列はQSAR toolの作成を担当した会社や大学などの名称です。
Tool No列には各QSAR toolに連番を与えています。
なお、同名のQSAR toolが複数回使われている例が散見されましたが、これらは別々のモデルであると考えることにしました。
そこで、QSAR tools (module)列では、同名のtoolには末尾に連番を付けて区別することにしました。
BA (%)、MCC、F1 score (%)はバランス精度などの評価指標です。
COV (%)はカバー率、すなわち、上記の性能評価に使用した化合物の全テストセット化合物に対する割合です。
評価指標順に並び替えることによって、前回の記事の内容を確認することができます。
これらの評価指標を対象として解析していきます。
評価指標は連続変数となっていますので、最初に見るべきは一変量の分布です。
では、見てみましょう。
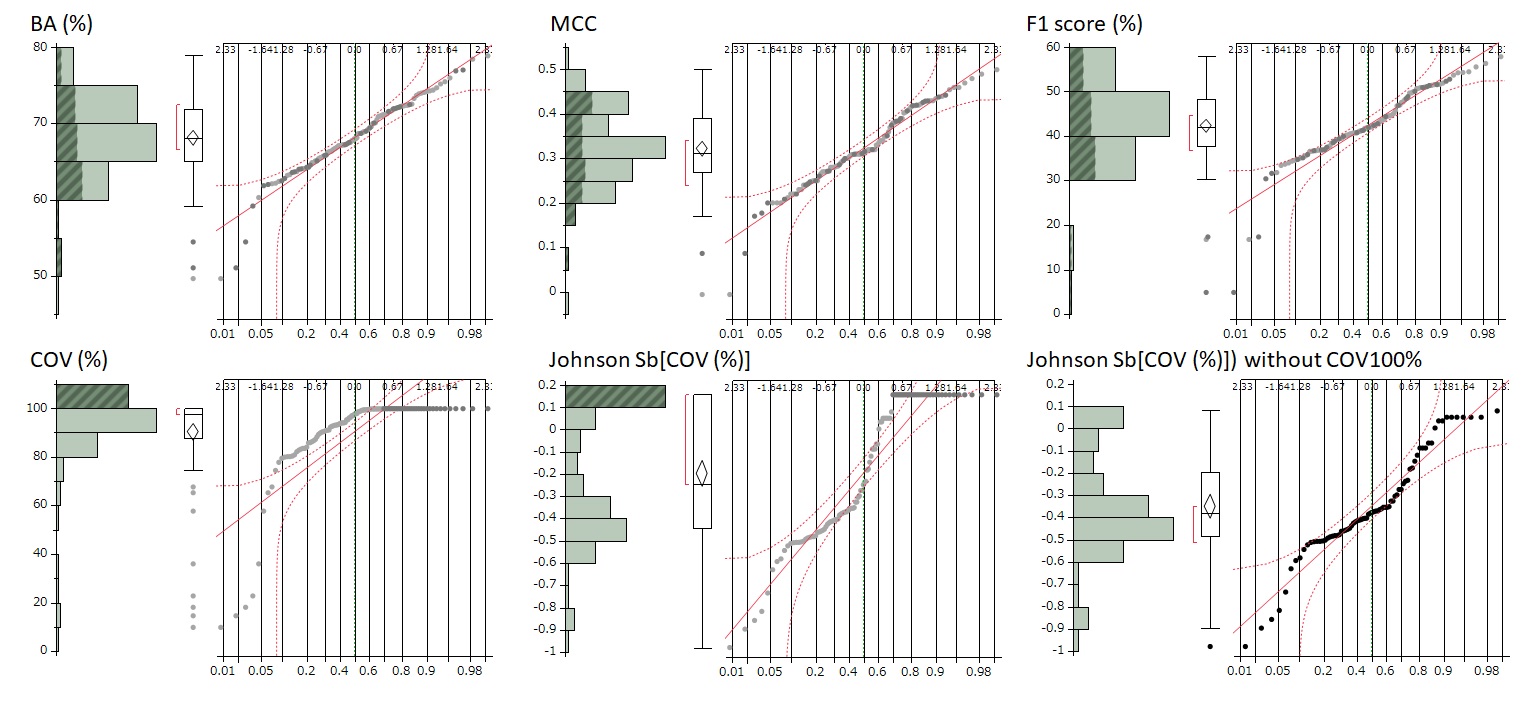
横棒グラフが分布の形状、プロットと赤い線からなるグラフが正規分位点プロットです。
プロットの一つ一つは予測モデルを示していて、全部で109種類あります。
正規分位点プロットの赤い直線上にプロットが並んでいると正規分布に近いことを意味します。
赤い破線は95%信頼区間で、ここからはみ出しているプロットが多いと正規分布から逸脱していることがわかります。
バランス精度、MCC、F1スコアはなかなか良く正規分布っぽい形になっています。
そこで、これらの統合評価指標はそのまま解析に使用していくことにします。
一方、カバー率(COV)は正規分布から大きく逸脱していることがわかります。
実はこれから回帰分析や主成分分析といった連続変数の比較解析を実施していく予定なのですが、そのような場合にカバー率のような極端な分布の偏りを持ったデータの扱いは難しいことが良く知られています。
そこで、カバー率をなんとか正規分布に近づけるような数値変換の努力をします。
しかし、カバー率は対数変換をうまく使っても正規分布化することができません。
このようなデータをシステマティックに正規分布化する強力な手法にJohnson正規化というのがあります。
カバー率をJohnson正規化した結果が、「Johnson Sb[COV(%)]」です。
さらに、ここから濃色で示されたカバー率100%の予測モデルを除外したのが「Johnson Sb[COV(%)] without COV100%」です。
ほぼ正規化が達成されているのが分かると思います。
そこで、カバー率の評価にはこのJohson正規分布化カバー率を採用することにします。
次は、バランス精度、MCC、F1スコアと3種類もある総合的評価指標を一つにまとめて統合的評価指標を構築してみます。
