Ames/QSAR国際チャレンジプロジェクトは、各回各フェーズで1600~4000種類程度の化合物に関するAmes試験の実測結果に対する予測精度を競う、というコンペでした。
しかし、提示されたブラインドテストセット化合物の全てを予測しなければいけないというわけではありません。
知識ベースの予測モデルの場合はデータベースに格納された部分構造等の情報から予測を達成するため、そもそも予測の俎上に載せることのできない化合物が出てきてしまう可能性があります。
統計ベースのQSARモデルであっても、予測には適さない化学空間が存在します。
極端な例を挙げれば、低分子化合物で構築された予測モデルは高分子化合物の予測には向きません。
QSAR予測モデルにおいて、予測に適する化学空間のことを適用領域(Applicability Domain)と言います。
適用領域を見極めるには高度な技術が要求されます。
そのためにはQSARモデルを構築するために使用したトレーニングセット化合物と類似した化合物をテストセットから選択する手法や予測確率を使う方法、それらを組み合わせる方法等が適用領域の決定のために使用されます。
ところが、化合物の類似度の指標も多様だったりするので、適用領域を決定する技術には多様な流儀が存在することになります。
Ames/QSAR国際チャレンジプロジェクトにおいて良い予測性能を達成するためには、
(1)予測性能の高いモデルを構築できる
(2)適切な適用領域を決定できる
の二つの要因をクリアする必要があります。
しかし、参加者よってはここら辺があまり良く分からないままコンペに参加していたように思います。
特に、私たちのように第2回から初めてコンペに参加したチームの多くにおいて、適用領域の設定に関する認識が不十分だったように思われます。
総計109モデルのなかで、カバー率100%のモデルは33種類(約30%)でした。
一方、第2回で初参加したチームが提出した33モデルなかで、カバー率100%のモデルは21種類、すなわち64%ものモデルがカバー率を設定していませんでした。
逆に、第1回第2回ともに参加したチームが第2回で提出したのは18モデルで、そのなかでカバー率100%のモデルはわずか4種類(22%)でした。
この64%と22%の相違はカイ二乗検定やFischerの正確検定でも次の図のように余裕で有意差が付きます(カイ二乗検定でP<0.005)。
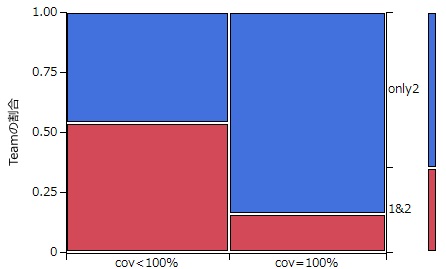
この図において、青は第2回で初参加したチームのモデル、赤は第1回第2回ともに参加したチームのモデルの第2回における割合を示します。
つまり、第1回Ames/QSARチャレンジに参加したことのあるチームは、カバー率に関して第2回に初参加したチームとは異なる認識をもってコンペに臨んでいたことになります。
さらに、第1回のフェーズ1,2,3と第2回(フェーズ4とします)におけるカバー率100%のモデルの割合を算定すると次のようになります。
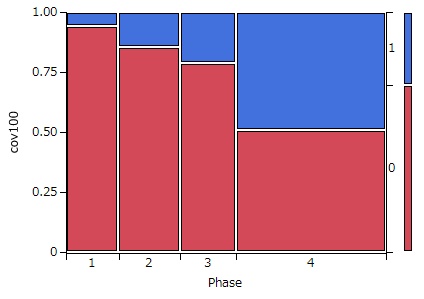
青はカバー率100%のモデル、赤はそれ以外のモデルの割合です。
時系列に従って、カバー率100%のモデルが単調に減っています。
これは、参加者がこのプロジェクトの評価法を学習した結果だと考えることができます。
第2回から初参加したチームはこのような学習を経ていないため不利だったと言えるかも知れません。
なんにしても、報告論文におけるモデルの評価はカバー率以外の評価指標でなされており、カバー率が高いことは推奨されても各モデルの評価にカバー率が使用されることはありませんでした。
なお、私たちは経済産業省AI-SHIPSプロジェクトなどの経験を通して適用領域に関する深い知識を持っていたのですが、上記の評価基準を充分に理解していなかったためにカバー率を下げ予測できる化合物を減らしてまで評価指標を向上させるという発想には至りませんでした。
ただし、このプロジェクトの本来の目的は予測性能の把握であって、参加チームの順位付けではありません。
よって、主催者側が評価に関する細かい説明をしていなくても、特に問題があるわけではありません。
第2回の論文も共著にしていただいているし、執筆過程にはいろいろな意見を取り入れてくださいました。
ただ、報告論文では表現し切れていない情報がたくさんあることも事実です。
以上の背景から、
(1)予測性能の高いモデルを構築できる
(2)適切な適用領域を決定できる
の二つを分離することによって、カバー率100%のときの真の予測性能を全てのモデルで推定してみましょう。
次のグラフがカバー率に対するバランス精度、MCC、F1スコア、およびPC1の相関です。
カバー率は正規分布化されています。
PC1はバランス精度、MCC、F1スコアを主成分分析によって統合した評価指標です。
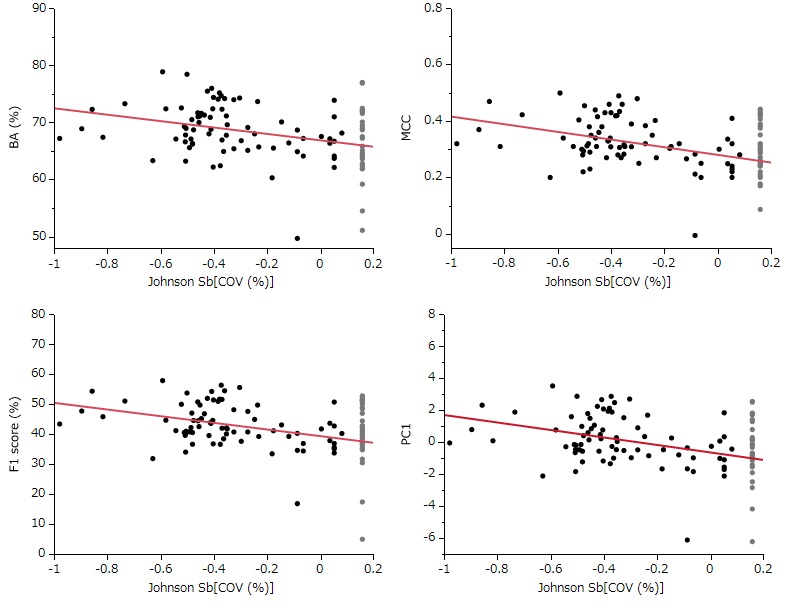
各点は予測モデルを示しています。グレーの点はカバー率100%のモデルです(直線の当てはめからは除外しています)。
全ての評価指標はカバー率と統計的に有意な負の相関を示しました。
やはり、カバー率を小さく設定すると性能の高いモデルが構築できる傾向が確認できました。
この知見はAmes/QSARプロジェクトにおいてカバー率の影響を示すことができた初めての成果です。
ただし、カバー率と予測性能の関係は統計的に有意とは言っても大きな残差を伴うこともわかります。
カバー率の設定には高度な技術を要し、現状では機械的に一律の作業というわけにはいきませんのでこのようなばらつきが見えてくるのだと考えられます。
最小二乗直線より上方に位置するモデルほど、真の予測性能と適用領域決定技術の双方が優秀だったということになります。
次は、これらの結果に基づいてカバー率が100%だったときの全ての予測モデルの評価指標を推定してみます。
