Ames/QSAR国際チャレンジプロジェクトで提出された予測モデルの傾向として、回答のために選択された化合物の種類が少ないほど性能が高い傾向にあることが分かりました。
テストセット化合物に対するカバー率の少ないモデルほど良好な予測性能を持っていたということで、直感的にも理解しやすい結果が得られました。
これは、当たらなそうな化合物を予め除外することによって予測の成績が向上する、と言い換えることができます。
一方、どうやらプロジェクトに参加したチームのカバー率に対する認識は必ずしも一定ではないらしい、ということもプロジェクト全体のデータ解析から見えてきました。
そこで、カバー率100%のときにはどのくらいの性能なのかを全てのモデルについて推定してみます。
推定方法には前回の解析結果であるカバー率と評価指標の最小二乗直線を使用します。
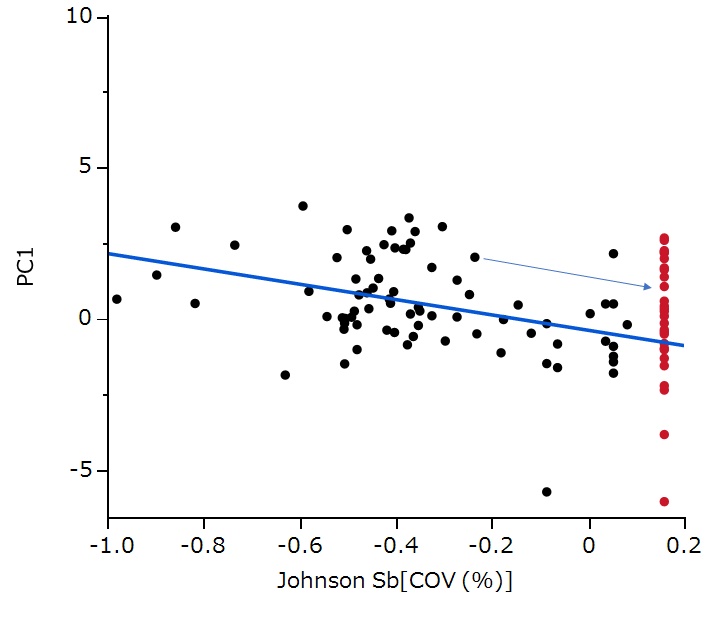
この直線は、カバー率を設定していた全てのモデルから算定されています。
全指標に関して負の傾きを持った直線が得られました。
バランス精度を例にすると
BA (%) = 66.9 – 5.62*Johnson Sb[COV (%)]
となります。
Johnson Sb[COV (%)]は
Johnson Sb[COV] = ln[ (COV − 4.9)/(100.063 − COV) ] × 0.111 − 0.655
の式で与えられます。
カバー率100%は正規分布化カバー率として0.158です。
これらから、カバー率100%のときのバランス精度を推定すると
BA (%) =66.0
となります。
これが、カバー率を設定した全77予測モデルから推定される、カバー率100%のときの平均的な予測性能ということになります。
一方、カバー率を設定していない(すなわちカバー率100%として提出された)33モデルの平均バランス精度は66.6でした。
設定しなかったモデルの実際のバランス精度とカバー率を設定したモデルからの推定値が良く一致したことから、これら両群のモデルの平均的な「真の性能(カバー率100%のときの性能)」のはほとんど同じであると推定されます。
では、次にカバー率を設定してあった全ての予測モデルの「真の性能(カバー率100%のときの性能)」を求めます。
求め方は単純で、各モデルの最小二乗直線からの残差をカバー率100の時のバランス精度の平均値に足し合わせるだけです。
この計算は、カバー率と評価指標の散布図における各プロットを、直線の傾きに沿ってカバー率100%(正規分布化カバー率として0.158)まで平行移動させることに相当します(上図の矢印参照)。
バランス精度と同様の計算をMCC、F1スコア、PC1でも行いました。
そして、カバー率を設定しなかった予測モデルと併せて
真の性能(カバー率100%のときの性能)表を完成しました。
上位20モデルの真の性能表を下に示します。109モデル全体の値はこちらから確認できます。
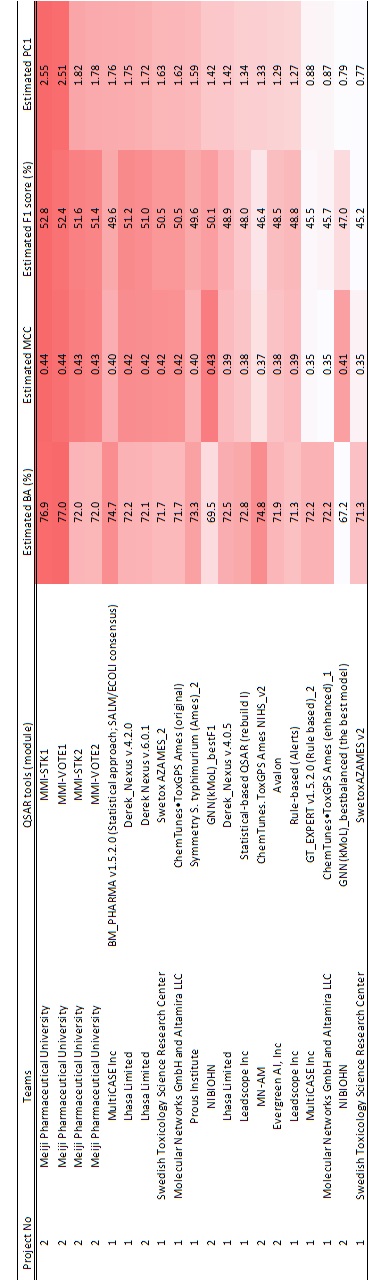
真のバランス精度が最良のモデルは
明治薬科大学のMMI-VOTE1でした!
真のMCCが最良のモデルは
明治薬科大学のMMI-STK1でした!
真のF1スコアが最良のモデルは
明治薬科大学のMMI-STK1でした!
そして、これらの統合的指標である真のPC1が最良のモデルは
明治薬科大学のMMI-STK1でした!
さらに、真の統合指標PC1の上位4種類のモデルは、性能の高い順に
1位:明治薬科大学のMMI-STK1
2位:明治薬科大学のMMI-VOTE1
3位:明治薬科大学のMMI-STK2
4位:明治薬科大学のMMI-VOTE2
でした。
私たちはこれらの4種類のモデルを第2回Ames/QSAR国際チャレンジに登録していましたので、
明治薬科大学が構築した全てのモデルが他のチーム・モデルを凌駕していたことになります。
本当はこういう解析を明治薬科大学以外の所属の方がやってくれると信憑性が高まるのですが、こんな面倒くさそうなことだれもやらないでしょう。。
せめて批判が可能なオープンなプレプリントサーバーに論文形式で格納することによって、解析の客観性を確保しました。
また、真の統合指標PC1における5位と6位は各々
MultiCASE社のBM PHARMAおよびLharsa社のDerec Nexusでした。
なお、以上の推定には大きな誤差が含まれている可能性があることに注意する必要があります。
次回はこれらの予測モデルについて概説します。
