第1回&第2回Ames/QSAR国際チャレンジプロジェクトに提出された109種類の予測結果を集計し、化合物のカバー率が100%だったときの予測性能を推定した結果、私たち明治薬科大学のグループが提出したMMI-STK1が最も優秀なモデルだった、というお話をしてきました。
ちなみに、MMI-STK1のMMIというのは私たちの研究室名である医療分子解析学(Medical Molecular Informatics)を意味しています。STK1というのは多数の機械学習のスタッキングモデルということです。
MMI-STK1はもともとカバー率100%の条件で予測結果を提出していましたが、もしカバー率を設定したら予測性能はさらに向上する可能性があります。
そこで、今度はカバー率の推移によって予測性能がどのように変動するのかを推定してみたいと思います。
なお、MMI-STK1のようなQSARモデルの場合は適用領域を適切に設定することによって予測性能を向上させることができます。
一方、不適切な適用領域を使用すると逆に性能が劣化することもあり得ます。
ここでは、第1回&第2回プロジェクトにおいてカバー率を設定した全ての予測モデルから得られる平均的な適用領域の影響を解析に使用します。
カバー率によって予測性能の評価指標(バランス精度、MCC、F1スコア、PC1)がどのように変動していくのかを推定するわけですが、この解析にも以前ご紹介した正規分布化カバー率と各評価指標の散布図を使用します。
これらの散布図では統計的に有意な最小二乗直線が設定できましたので、これらの直線の傾きを使って種々カバー率におけるMMI-STK1の評価指標を推定します。
この直線からカバー率100%のときの各評価指標を求め、これの平均値とMMI-STK1の評価値の残差を直線に足し合わせることによって計算します。
この作業は、カバー率100%のときのMMI-STK1の評価値を直線に沿って平行移動させることに相当します(下図参照)。
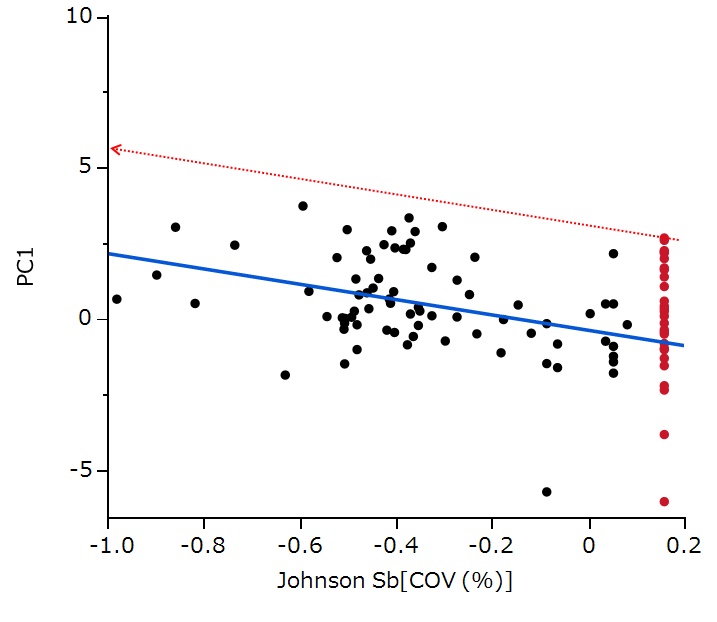
この図の横軸はJohnsonの方法で正規分布化されたカバー率ですが、この変換は非線形ですのでわかりにくいと思います。
そこで、横軸を元のカバー率に直して描画し直したのが次の図です。
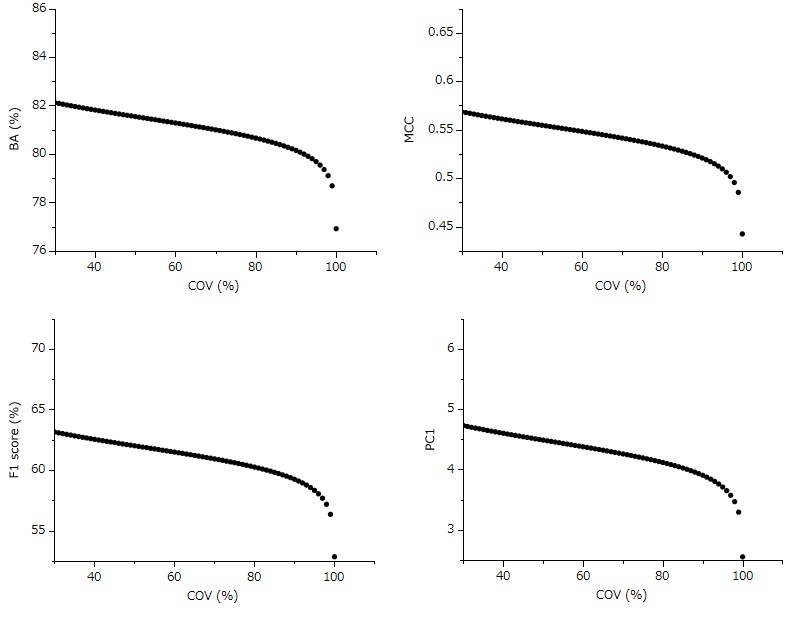
全ての評価指標において、100%から少しカバー率を落とすと大幅に性能が向上していることがわかります。
例えば、カバー率100%におけるMMI-STK1のF1スコアは52.8%でしたが、カバー率が90%になると59.2%まで上昇しています。その後の性能向上はなだらかで、60%と30%のときのF1スコアは61.5および63.1と推定されました。
この観察は、QSAR予測モデルでは予測が困難であった少数の化合物がブラインドテストセットの中に含まれていたことを示唆していると考えることができます。
このような解析は、予測性能とカバー率のバランスを勘案するために有用な情報になると思います。
また、Ames/QSAR国際チャレンジプロジェクトは、公表されていない化合物に対するAmes試験の実測値を使用し、厳密に管理されたコンペ形式で予測モデルの予測性能を評価しています。
すでに実測値が公開されてしまっている化合物は既存のモデルのトレーニングに使用されている可能性がありますので、厳密なモデルの評価には使用できません。
その意味で、このプロジェクトの意義は極めて大きいと思います。
そして、このプロジェクトで得られた最高性能モデルであるMMI-STK1は現時点におけるin silico変異原性予測の到達点であると考えて良いのではないでしょうか。
今回はカバー率の影響を全てのモデルから推定しました。
これは、適用領域の化学空間を決定するために標準的な技術を適用したことに相当します。
以前少し述べましたが、私たちはモデル構築だけではなく、適用領域と化学空間に関する深い知識を持っていますので、カバー率の設定によって実際にはもう少し高い予測性能が実現できたのではないかと考えています。
最後にQSARモデルの可能性について。
Ames試験の実測結果にはある程度の(結構大きな)誤差が含まれていることが知られていますので、実測結果を用いたトレーニングの結果として構築される予測モデルにもこの誤差が反映されます。
しかし、曖昧な実験結果であっても多数の平均が真の値に近似していくように、多数の化合物から構築された理想的なQSARモデルはもしかしたらAmes試験自体の誤差を克服できるかも知れません。
残念なことに、答え合わせに使用される実測値にも誤差が含まれていますので、上記の証明は困難だと思いますが。。
